ARM lanzó su primer chip propio y Meta ya es su cliente: lo que el AGI 910 significa para la IA en LATAM
ARM dejó de solo vender licencias y ahora tiene su propio silicio para IA. El AGI 910 disparó la acción 16%, Meta firmó de primero y esto cambia el juego para startups en México y LATAM.
Durante 35 años, ARM fue la empresa que le vendía planos a todos pero nunca construyó nada. Qualcomm, Apple, Samsung, MediaTek: todos han hecho chips con arquitectura ARM. La empresa cobraba regalías y vivía feliz. Eso se acabó.
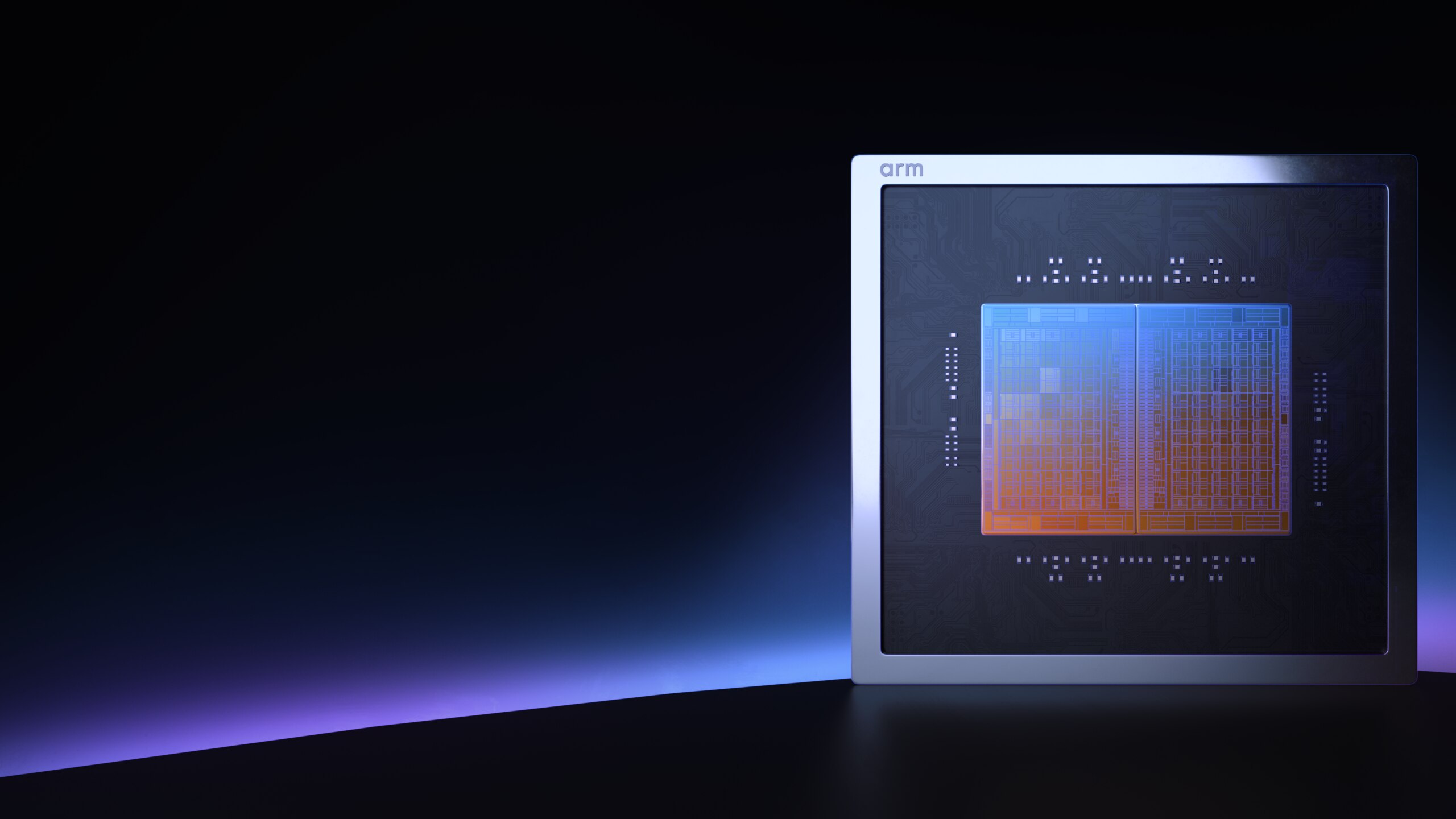
El 24 de marzo de 2026, ARM anunció su primer chip propio de producción: el AGI 910 Series CPU, diseñado específicamente para correr inferencia de IA en centros de datos. Meta firmó como primer cliente. La acción subió 16.38% en un día, el mayor salto desde su IPO en 2023. Y la pregunta que nadie en LATAM se está haciendo todavía es: ¿qué cambia para nosotros?
Qué es el AGI 910 y por qué importa
No es una GPU. Es un CPU de 136 núcleos Neoverse V3 fabricado en el proceso 3nm de TSMC, con 12 canales DDR5 (hasta DDR5-8800), 96 líneas PCIe Gen6 y soporte nativo CXL 3.0. ARM dice que mete el doble de rendimiento por rack versus arquitecturas x86, y hasta 8,000 núcleos por rack enfriado con aire en configuración ORv3 de 36kW.
El chip no va contra NVIDIA. Va contra AMD EPYC e Intel Xeon, que dominan los servidores de inferencia. Y según el anuncio oficial de ARM en su newsroom, la apuesta es clara: el mundo ya entrenó sus modelos, ahora tiene que correrlos a escala. Ahí es donde entra el AGI 910.
La lógica financiera también está bien pensada. Antes, ARM cobraba regalías sobre cada chip que sus licenciatarios vendían. Con silicio propio, se queda con todo el margen de manufactura. Para 2031, ARM proyecta generar $15,000 millones en ingresos solo de esta línea de chips, partiendo de los $4,000 millones actuales de toda la empresa.
Meta, OpenAI y los otros que ya firmaron
Meta es el cliente estrella y co-desarrollador del chip. No es coincidencia: los modelos Llama 4 (Scout, Maverick y el próximo Behemoth) fueron optimizados de origen para correr sobre silicio ARM. Básicamente construyeron el chip y el modelo juntos, como un stack vertical. Meta lo confirmó en su propio blog.
Pero no es el único. OpenAI, Cloudflare y SAP también están en la lista de clientes comprometidos. Para los servidores físicos, ya hay hardware disponible para ordenar de ASRock Rack, Lenovo, Supermicro y QCT, con disponibilidad amplia esperada para el segundo semestre de 2026.
El giro histórico que Wall Street sí entendió
La acción de ARM Holdings pasó de $51 en su IPO de septiembre de 2023 a $157.07 el 26 de marzo de 2026, un incremento del 208%. El salto de 16% del 25 de marzo fue el mayor movimiento en un día desde que salió a bolsa. Guggenheim le puso precio objetivo con 78% de upside todavía desde ese nivel.
Fast Company lo describió como “el mayor giro en los 35 años de historia de la empresa”. No es exagerado. ARM pasó de ser proveedor de planos arquitectónicos a jugador de silicio en el mercado de IA más caliente de la historia.
La era de la inferencia: qué significa para México y LATAM
Aquí está el ángulo que nadie en la región está discutiendo: estamos saliendo de la era del entrenamiento y entrando a la era de la inferencia.
Durante 2022-2024, la guerra era por quien entrenaba los mejores modelos. Eso requería NVIDIA H100s a $30,000 dólares el GPU, clústeres de miles de unidades, y presupuestos de cientos de millones. Territorio de OpenAI, Google, Meta y Anthropic. Las startups de LATAM ni se asomaban.
La inferencia es diferente. Es correr modelos ya entrenados para responder preguntas, procesar documentos, automatizar tareas. Requiere eficiencia, no potencia bruta. Y si ARM puede entregar 2x rendimiento por watt versus x86 en inferencia, los proveedores de nube que adopten AGI 910 van a bajar costos de API. Eso sí llega a las startups mexicanas y latinoamericanas.
Ya estamos viendo el precedente: AWS Graviton (también ARM) ofrece instancias hasta 40% más baratas que sus equivalentes x86. Los costos de IA en la nube son el cuello de botella principal para empresas chicas en México. Menos costo por inferencia = más accesible para todos.
Como analizamos en cómo los agentes inteligentes bajaron 76% el robo de carga en solo 3 meses, las empresas mexicanas que ya están experimentando con agentes de IA van a necesitar inferencia barata y constante. El AGI 910 apunta exactamente a ese mercado.
Lo que no está resuelto todavía
ARM tiene 12 canales DDR5 en el AGI 910. AMD EPYC Genoa/Turin tiene 16 canales con MRDIMM. Para workloads que necesitan un chingo de ancho de banda de memoria, el x86 todavía tiene ventaja en papel. ARM lo reconoce y dice que AMD e Intel van a tener sus actualizaciones de 16 canales más adelante en 2026. La batalla no está ganada.
Tampoco hay precios públicos todavía. Para comprar un servidor AGI 910 hay que contactar directamente a Lenovo, Supermicro o ASRock. No es solución lista para startups que empiezan, al menos por ahora.
Y está la pregunta de los modelos: si Llama 4 está optimizado para ARM y tus workloads corren sobre modelos que no fueron entrenados pensando en esta arquitectura, la ventaja baja. La integración Meta-ARM es una apuesta a que Llama se convierte en el modelo dominante de inferencia empresarial. Puede pasar, o puede no pasar.
Vale la pena seguir de cerca la discusión sobre la burbuja de IA en Wall Street: ARM subió 16% en un día, pero el mercado sigue preguntando quién realmente va a monetizar toda esta infraestructura a largo plazo.
La neta del negocio
ARM dejó de ser el proveedor de planos y quiere ser el constructor. Es un movimiento lógico: durante años vio cómo Apple, con sus chips M-series basados en arquitectura ARM, se convirtió en la empresa más valiosa del mundo. Ahora quiere su pedazo del pastel de centros de datos.
Para México y LATAM la señal más importante no es el chip en sí, sino el cambio de paradigma: la infraestructura de IA se está volviendo más eficiente y, eventualmente, más accesible. Las startups que hoy se frenan por costos de inferencia van a tener más opciones en los próximos dos años.
¿Ya estás usando APIs de IA para tu negocio o proyecto? ¿Los costos son el principal obstáculo? Cuéntanos en los comentarios.
Fuentes
- ARM Newsroom: Arm expands compute platform to silicon products
- CNBC: Arm stock jumps 16% as company expects revenue windfall from new chip
- Meta: Meta Partners With Arm to Develop New Class of Data Center Silicon
- ServeTheHome: Arm AGI CPU Launched Establishing Arm as a Silicon Provider
- Fast Company: ARM stock price surges today after chip designer announces biggest pivot in its 35-year history
- FinancialContent: Arm Holdings (ARM): The AGI Pivot and the Meta Alliance
Comentarios
No te pierdas ningún post
Recibe lo nuevo de Al Chile Tech directo en tu correo. Sin spam.
También te puede interesar

20,000 despidos en 48 horas: Meta y Microsoft dispararon el gatillo y la crisis laboral por IA ya llegó a México
Meta recorta 8,000 empleados, Microsoft ofrece retiro voluntario a otros 9,000 y el contador 2026 ya supera los 96,000 despedidos en tech. Esto es diferente a 2022. Te explicamos qué perfiles están en riesgo en México y qué habilidades te salvan.

Meta compró una startup de robots humanoides mientras despide a 8,000 personas: la contradicción que define el capitalismo de IA en 2026
El 1 de mayo Meta adquirió Assured Robot Intelligence para construir robots humanoides con IA, y el 20 de mayo va a correr a 8,000 empleados. El panorama para la manufactura mexicana se pone cada vez más tenso.

Meta traicionó el open source: Muse Spark es su primer modelo cerrado y le está cobrando la factura a millones de devs
Meta lanzó Muse Spark, su primer modelo de IA propietario y cerrado, rompiendo con años de filosofía open source. Llega tarde, cuesta más y deja a los devs de LATAM en la incertidumbre.